How to Connect Bunny to RQUEST
BC|Platforms RQUEST is Bunny compatible, and Bunny can retrieve, execute, and return tasks and corresponding results to it. This guide will help you connect Bunny on a virtual machine or locally to a RQUEST instance, but the general guidance is suitable for connecting any instance of Bunny to RQUEST.
To support RQUEST, you’ll need two Bunnies running to execute the two different query types currently supported; Availability and Distribution.
As Bunny is a lightweight tool, it’s simple to run multiple Bunnies in deployed environments and using Docker Compose on a virtual machine or locally. We provide a sample docker compose file for multiple Bunnies as well.
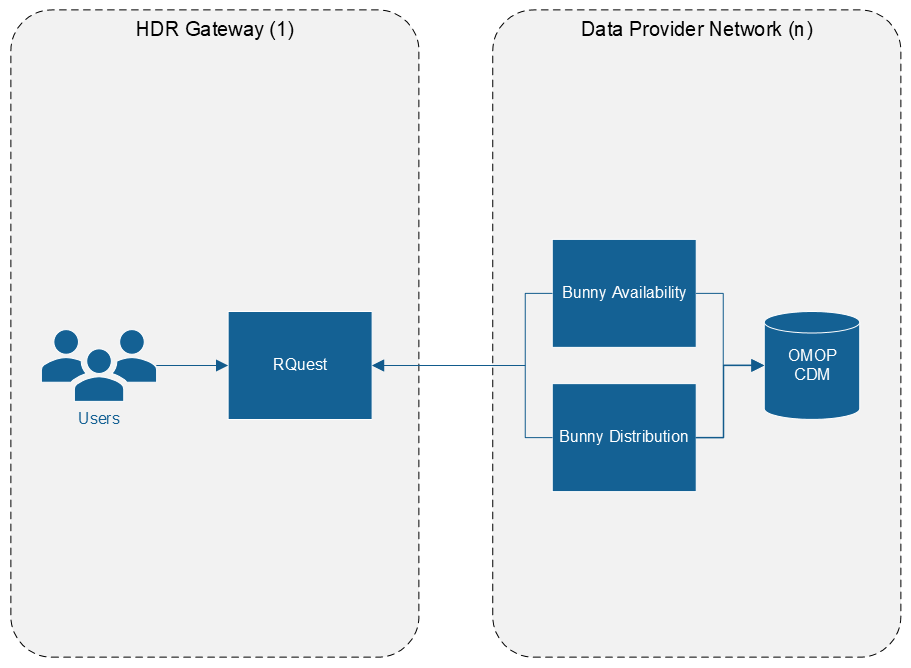 A deployment of multiple Bunnies (a fluffle) connecting directly to RQUEST.
A deployment of multiple Bunnies (a fluffle) connecting directly to RQUEST.
Connecting Steps
1. Get RQUEST API Details
You will need the URL for the RQUEST API, this will look something like: https://rquest.example.com/link_connector_api
And you will need the authentication credentials to connect with, these will be a username, and password.
How to get these can be found in your supplied documentation for RQUEST.
2. Get a Collection ID
In RQUEST you can create a new collection for Bunny, or use an existing one.
Inside the section Admin and Collections list, select the “Info” of the Collection you want to connect to.
Here you can see the Details of the Collection, that include the “Collection Acronym”, copy this as the collection_id.
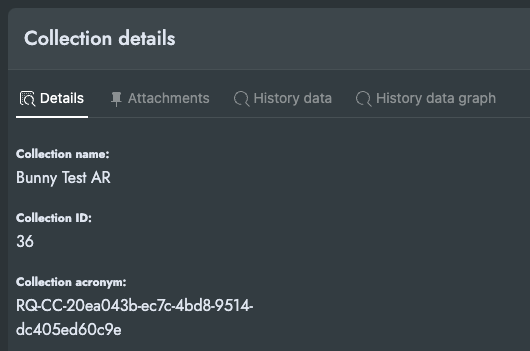
If you cannot access the admin section of RQUEST, contact your RQUEST administrator for these details.
3. Compose multiple Bunnies (a fluffle)
As the configuration for the database and API is now shared between Bunnies, it’s simplest to store this inside the environment variables in .env
The sample Docker Compose is now much simpler, and the only difference in configuration between Bunnies is the TASK_API_TYPE.
name: rquest-bunny
services:
availa-bunny:
image: ghcr.io/health-informatics-uon/hutch/bunny:edge
env_file:
- .env
environment:
- TASK_API_TYPE=a
distri-bunny:
image: ghcr.io/health-informatics-uon/hutch/bunny:edge
env_file:
- .env
environment:
- TASK_API_TYPE=bAnd more detailed configuration for both Bunnies is inside the .env file or your environment variables.
DATASOURCE_DB_USERNAME=postgres
DATASOURCE_DB_PASSWORD=postgres
DATASOURCE_DB_DATABASE=omop
DATASOURCE_DB_DRIVERNAME=postgresql
DATASOURCE_DB_SCHEMA=public
DATASOURCE_DB_PORT=5432
DATASOURCE_DB_HOST=localhost
LOW_NUMBER_SUPPRESSION_THRESHOLD=5
ROUNDING_TARGET=10
POLLING_INTERVAL=5
TASK_API_BASE_URL=http://rquest.example.com/link_connector_api
TASK_API_USERNAME=changeme
TASK_API_PASSWORD=changeme
COLLECTION_ID=changeme4. Update environment variables
Make sure your environment variables match what you retrieved from RQUEST:
TASK_API_BASE_URL=http://rquest.example.com/link_connector_api
TASK_API_USERNAME=#RQUEST API Username
TASK_API_PASSWORD=#RQUEST API Password
COLLECTION_ID=#RQUEST Collection Acronym5. Running the Bunny Fluffle
Your configuration and containers should now be correctly configured. You can now run the fluffle of Bunnies with:
docker compose -f bunny-rquest.compose.yml up -dYour Bunnies should now be running, and checking RQUEST for tasks.
6. Run a Availability Query
Now it’s time to run a query with RQUEST, starting with availability.
This query is handled by the availa-bunny service, if you create a new query against your collection, and run it.
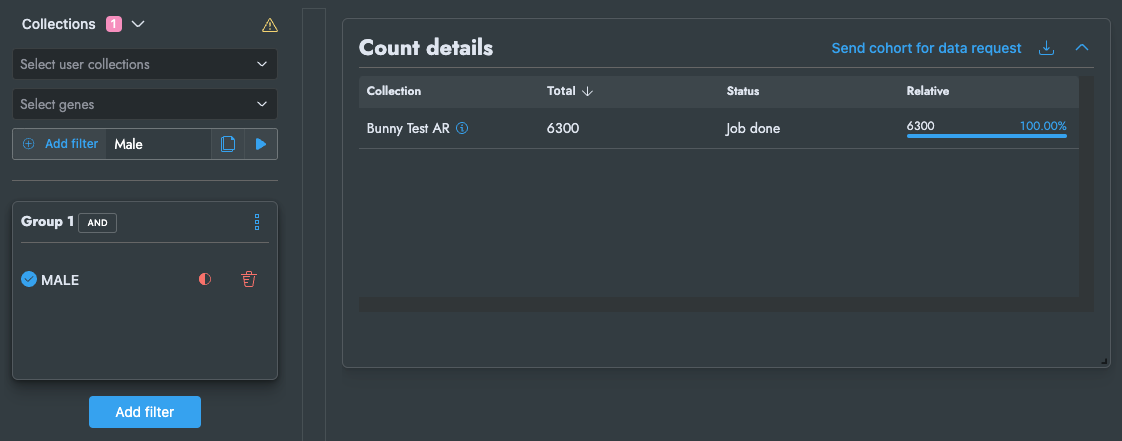
You should see your tasks be queued, executed in your local logs, and returned to RQUEST.
7. Run a Distribution Query
To populate the collection with distribution data, a Distribution query is handled by the distri-bunny service.
These are triggered on a scheduled basis by RQUEST, your Bunny will pick one up when it is triggered.